
We all know how necessary data is and even more so «good data» to be able to exercise the cool task of Data Science. In my case, one of the recurring tasks to obtain that data is the scraping of websites to be able to then analyze the data or generate and automate tasks of my day-to-day.
The most aseptic and simple way to scrap a website is to connect with the request library and extract the Html code that we will then deal with a library such as beautifoulsoup or similar trying to extract from the Html code the tags that interest us to collect the data … and it works very well!! Fast and efficient. But unfortunately, every time we find websites that use javascript code that makes the Html code composed, on the side of the local browser and not on the server, which makes this action much more difficult and makes scraping a not so cool task, forcing us to analyze the web to look for alternatives to extract its Html code.
We are going to expose here two use cases that can occur in this type of website, let’s start with the first in this first part:
1. In search of the lost .json.
As we said this type of website, when making a “request” provides us with an Html code that has nothing to do with what is shown on the web of our browser. For example, if we enter this website of calls for aid and financing of entrepreneurship projects of Banco Santander (https://www.santanderx.com/calls) there are a lot of data on calls that would be great to collect and be able to analyze to study where it puts its efforts in supporting university entrepreneurship. It would be great to connect and get the html that provides us with the tags where to extract the data, but in doing so… disappointment… shows us a «skeletal» Html.
But what we observe is that there are tags <script> that give us a clue that there are javascript functions that will generate the Html when requested by the browser. Meanwhile, it asks us to use a compatible browser…😞.
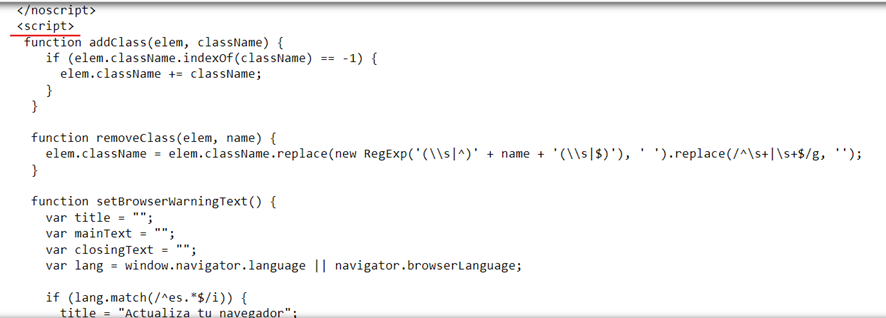
This forces us, as we already anticipated, to analyze that website and functions to check how it uses those javascript functions to extract the data from the server and display it in the browser.
To check it out, I use a very interesting feature in Firefox’s «Inspect» functionality. This is the Firefox Network analysis, which basically tells us the process of loading the different functions and data from the server to the browser.
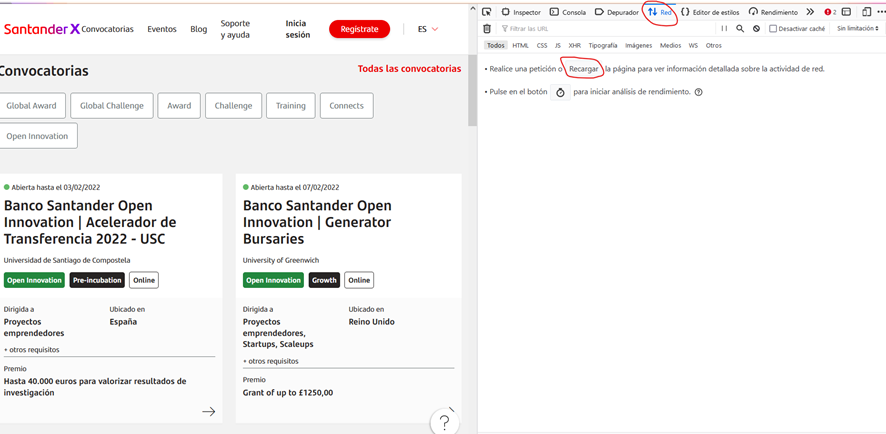
When reloading the web, it generates the entire process of requesting data and code to the server that will show us successively:
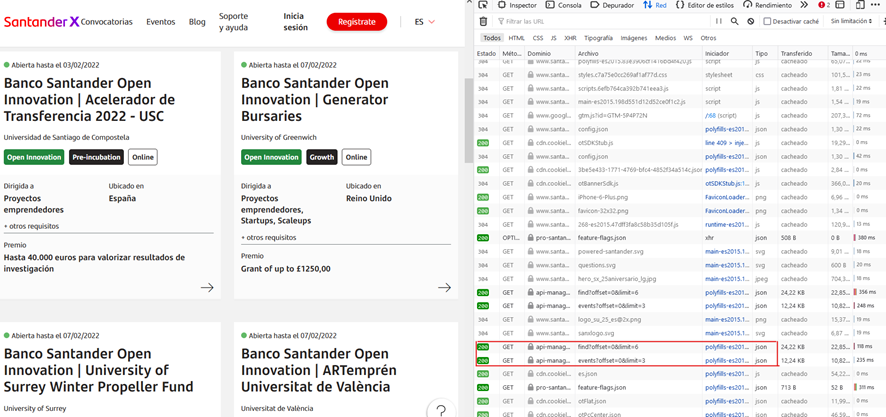
Here, we must look at how it requests the data, in this case, it shows us two .json files that the server seems to return with the call and event data that is displayed in the browser. If we copy that url (right button above) and put it in the browser… voila! We obtain the complete data of the 6 calls that appear in the first place of the cover.
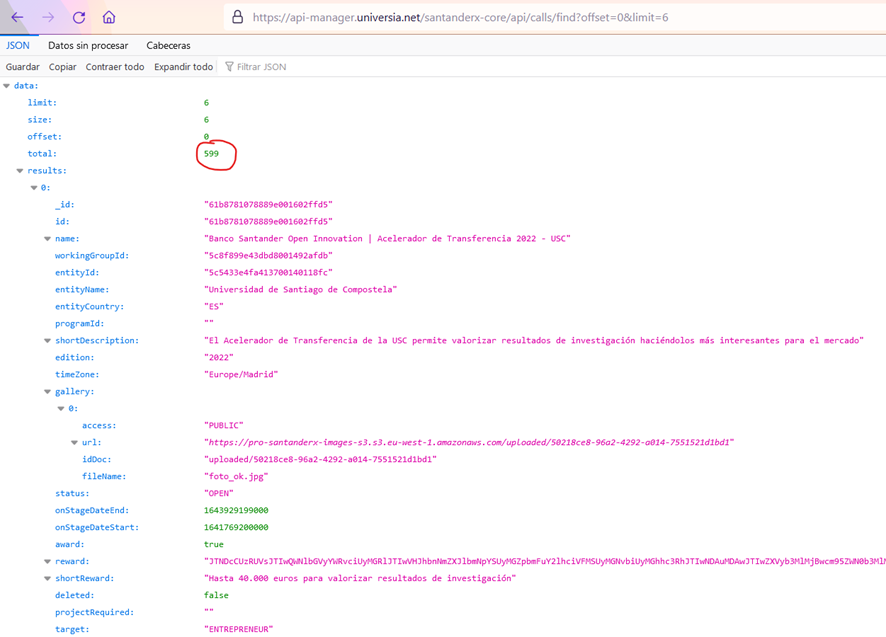
But we must notice that it tells us that there are a total of 600 calls, so we can play with the api rest (url) so as not to limit the number to 6 and thus obtain the complete data: https://api-manager.universia.net/santanderx-core/api/calls/find?offset=0&limit=6, we will change the 6 by 600 and we will obtain the .json with all the data of the calls that interest us. In the same way, we can do with the other url for events.
From here, we only have to treat the json in Python and import it to Pandas to work on the analysis of the data.
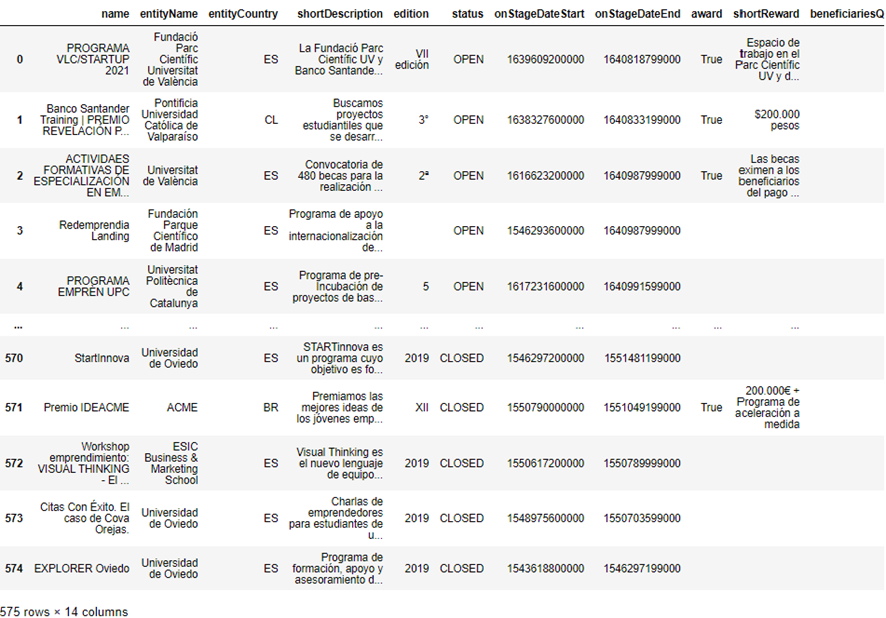
 In my Github repository, I leave the Jupyter of data extraction and analysis if you want to dig a little deeper.
In my Github repository, I leave the Jupyter of data extraction and analysis if you want to dig a little deeper.


