
As I said in previous articles scraping data from websites is quite rewarding, not only to obtain data, but to automate day-to-day tasks that can consume a lot of your time.
It is common to face a website and its html code (when there isn´t javascript in between) to download data from html tags that are repeated sequentially and finally pass it to a corduroy dataframe to work with them or report it to a department that uses it.
Accessing these tags and extracting the data is relatively simple. Let’s take as an example, the website of Fellows with grants received from a Banking Foundation for the promotion of science. In this case, the objective was to extract the complete list of fellows and some of their data (only in Europe there are more than 4,400 students registered) to later make an analysis of various fields to have global information, scientific areas of greater interest, detect talent hotspots, mentors with greater potential, etc.
In this case, I want to detect the fellows in Spain to have a complete record and analyze it later. But in these cases, a drawback arises and are the cases of the tokens that do not have the tags of some of the data that we are collecting, with which the loops of «for» we get lists of different sizes so that then it becomes impossible to form a single homogeneous dataframe. In these cases, let’s see a way to solve it.
We start by loading the necessary libraries.
We check that it does not give us an access error (code 200), for this, we need to configure the header to be able to inform the server with additional information about the request and that the request looks more like a browser.

We parse the html code with the BeautifulSoup library and start extracting data.

For example, if we want to extract the names, in this case from the first record that appears in the tag <a>:

If we wanted to extract the entire list of names:

So far, no problem… but with the same method, we begin to extract the rest of the data in which we are interested and when checking the length of the lists … wow!!, we see that they are not the same so we can not generate a dataframe in a simple way.
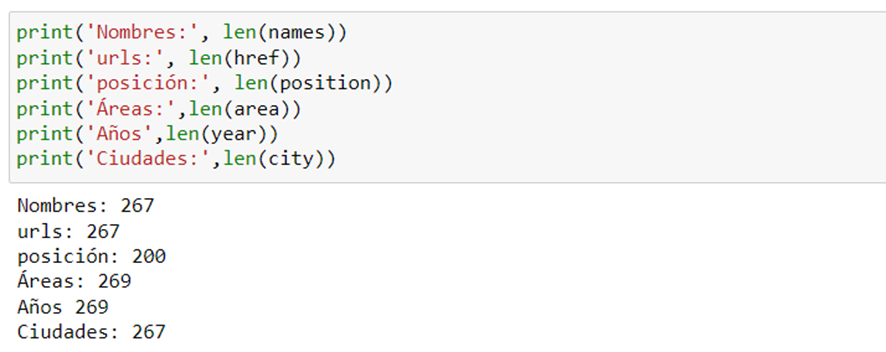
That indicates that there are tags that do not exist in certain files of the fellows and that generates a problem of missing values that must be solved in such a way that when it does not find the tag it generates an N / A.
This is where I provide a possible solution that has worked for me. It will be necessary to make a loop on the list and not on the range of the list, we create a key dictionary: value that we will fill in and when you do not find the tag, add a lost value. It could look something like this:
Now it will only be left to pass the dictionary to pandas with the zip object to generate the dataframe.

In this article, we have learned to deal with the values lost in the extraction of data from an html code due to a lack of tags. Something relatively easy to solve, but that took me a while to solve, so, if readers can save a while, it will be great!!!
If you are interested you can see more projects in my Github profile 


