
Objetive:
Among my professional tasks, one of them is to explore public grants that may be published for scientific projects or projects of my own organization and send them to the corresponding departments as part of a Science&technological scouting system. It´s a repetitive and time-consuming task, so I thought about developing a small application that will automate this process and free up my time for other tasks.
That´s why in this post I´ll describe in a simplified way an application that automates the personalized search in a Spanish database of grants and subsidies, the capture of information, and its sending through a notification through Teams of Microsoft.
Description of the technical development of the App
We´ll connect to a Spanish public database that uses Java / Ajax as a framework so BeautifulSoup is not designed to invoke JavaScript functions so I use the Selenium library as an alternative to extract the information since it imitates in the browser what a user would do to make a query.
Below, we describe the most general steps for application development:
1. Web scraping
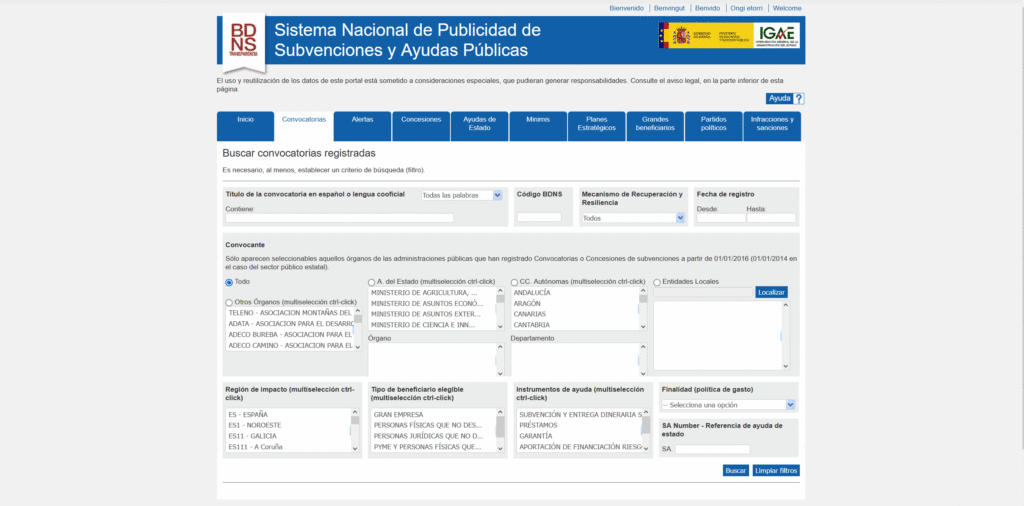
URL: https://www.pap.hacienda.gob.es/bdnstrans/GE/es/convocatorias
The way to extract the HTML code is analyzed. Being a search form and filtering that uses javascript, it´s not possible to use request and Beautifulsoup alone. It provides us with a code that does not correspond to the web.
I try to locate with Firefox>Inspection>Network the json document from which the javascript can be fed to show the search filtering. If this json is achieved it would be enough, since it has a URL in API format that can be managed to expand or filter results, so we would have the data we want.
When trying to request over the json, they produce continuous SSL certificate errors. After performing many tests on the code through different headers, the introduction of cookies, the update of the SSL certificate, Python SSL library, etc … It´s impossible to use the JSON document.
To confirm which technology the proposed web framework uses, we can use the https://builtwith.com/ application, entering the URL. In this case, we confirm that it uses a framework that complicates the use of request and BeautifulSoup.
The next alternative is to scrape with Selenium, which is a library that clones the browser and does the same functions that we can do manually, but automatically. The main difficulty is to download and place the browser drivers, in this case, I choose the Firefox driver. The key at this point is to locate the file in the same path as the Python.exe of the Python environment with which we are open in Jupyter notebook.
From here we generate code to clone the actions, we would do in the browser in the search form. After several tests, it seems that the action is done properly until obtaining the search for selected calls. The key at this point is to select text or values in the search fields using “Select(driver.find_element_by_xpath())”. To select the xPath of each field it is best in firefox to put yourself in the field and with the right button select «Inspect» and then copy xPath.
Then put the simple code of a simple query into the proposed database:
Once the result is obtained, Selenium has the method «element.get_attribute (‘innerHTML’)» that extracts the HTML code below a certain tag, in our case, we take the tag <table> that appears in the search and thus we get the data of the HTML code of the table with the data that interests us for the notifications.
We pass this to a dataframe (DF) with which we can already save the data and move on to the next stage of the app.
One of the most interesting fields for this type of communication is the link so that the user who is interested can expand the information. But in Teams, we have a limitation by space in the way notifications are presented, so it is interesting to shorten the URL to generate space for the rest of the fields.
For this, we have used the pyshorteners library and its «Chilpit» object that in a free way without having to use any APIKey can be shortened, there are other options, but you have to register.
Once we have the data in the DF, the main difficulty is that notifications are only sent if it finds a not repeted records. To do this, we must save the DF of the first search and compare it with the DF of the most recent search. I ended up doing that with “df.concat(df1, df2)” and then with the “drop_duplicates()” property, with the “subset=” attribute so that it deletes when comparing only with a field in the DF, in this case, the BD_Code which is a unique number in each record.
At this point, I found a difficulty, typical of these data since the “drop_duplicates()” did not seem to work, since the data that was dumped to the DF was of type «string» but when saving them to the csv and retrieving them for comparison, I treated them as type object. So it has been necessary to secure the types with the “to_string()” property of pandas.
2. Send a notification to Teams
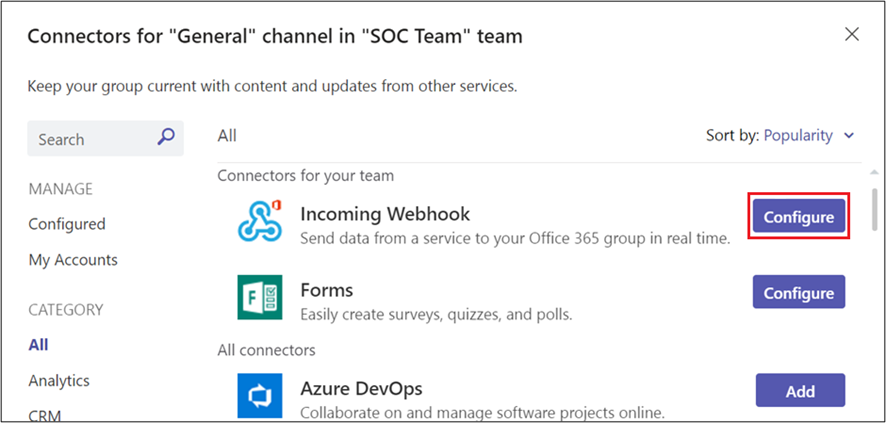
Prior to this, in the Teams, in the channels, we have the option to open connectors for external notifications through the «Incoming Webhook» application. In the channel, at the three points of the channel (General), we select connectors:

When configuring, we create a new connector which it can be customized with a specific logo, we create it and copy the URL that is generated and with which we will connect with the channel.
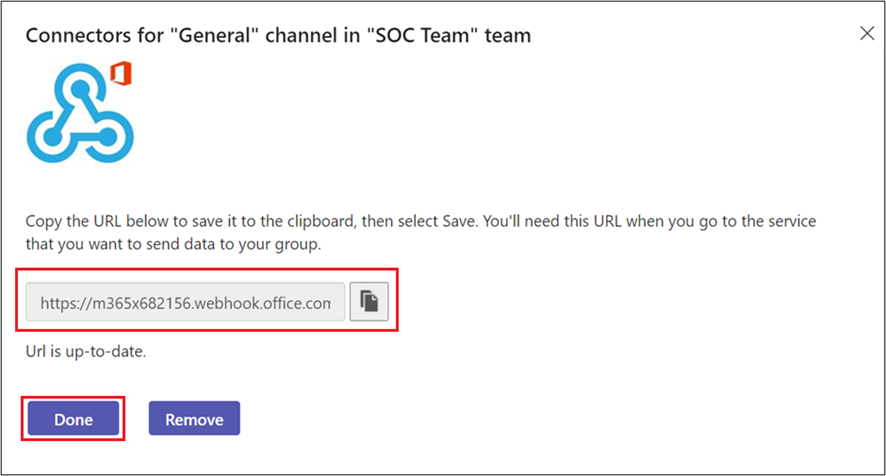
With this URL we can already install the Python pymsteams library, with which we can easily send notifications to the Teams channel, entering the generated URL of the channel by generating a function callable later.
It´s important to note that the import of the library must be done within the function for it to work properly.
Finally, we call the notification-sending function integrated into a loop if we get new records or not.
3. Conclusions
In this article, we have learned to face complicated websites to scrape because they are built with a framework in java and javascript and how to take advantage to generate a small application that sends notifications to different Teams channels to be aware of information of interest in a personalized way. We would need how to automate to run the script at the time we are interested, here we can go through containing the application with Docker and putting it on a server or through our Tares administrator in a Windows … This will be the subject of some other post.
If you are interested you can see more projects in my Github profile 

