They are used to recommend, for example, to people who have made a particular purchase, what other products might interest you. There are several types of recommendation models.
- Content-based Recommendation Model
This group of algorithms relies on using the description of each product to recommend, without using information from other users to generate the recommendation to the target user. - Collaborative Filters-based Recommendation Model
Recommendation systems based on user actions. The actions of the users give us information about their own tastes and information of the products themselves. An example might be the Co-occurrence model: To define which products will be recommended you use the co-occurrence matrix that shows which other products purchased the users who purchased that product.
In this tutorial we will work with the MovieLens dataset that contains movie ratings. Stable benchmark dataset. We’ll work with the MovieLens 1M Dataset file have 1 million ratings from 6000 users on 4000 movies. Released 2/2003.
Loading data
We check what content the zip of the data has, before downloading and unzip and load the movie file separated by «::» in pandas.
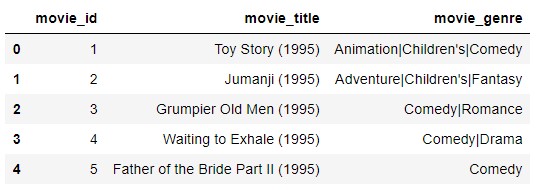
Collaborative Filters-based recommendation model🎬👨👩👧👦
This group of algorithms relies on using the description of each product to recommend, without using information from other users to generate the recommendation to the target user.
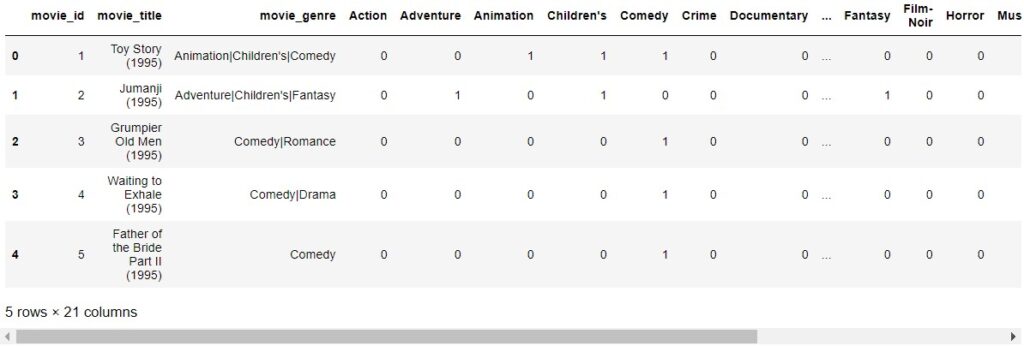
The get_dummies function converts a categorical variable into multiple columns.
For each movie, these dummy columns will have a value of 1 when it matches their topic.

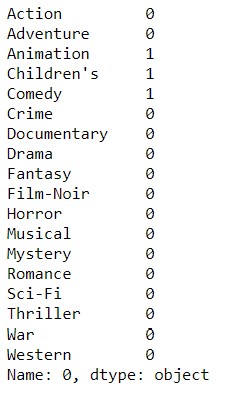
We identify a type user, rating 1-5 the tastes of each of the categories of movies.

We generate three functions, the first to make the vector product of two vectors and other función to make the vector product of a movie and a user, and finally, others to calculate the recommendation value of all movies in the dataset for a user and recommends the best movies.
We get the genres of for example the first film, Toy Story.

We now test with the preferences of our model user…

Content-based recommendation model 🎬📽
This group of algorithms relies on using the description of each product to recommend, without using information from other users to generate the recommendation to the target user.
We load the file with movie scores, ratings.dat file, is a set of users with the movies they’ve seen and their punuation. We replace the id of the movie with its title for greater clarity, so we use the spread merge of pandas to join movie.dat and rantings.dat from the variable movie_id.

We create a new matrix with the ratios of each user for all movies.
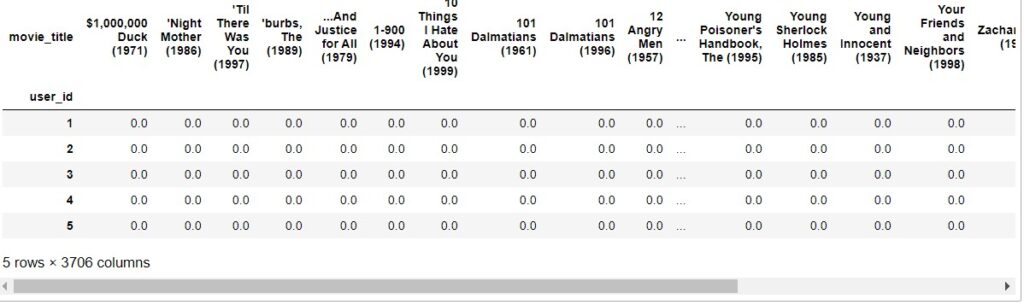
We calculate the correlation (Pearson correlation coefficient(PMCC)) between movies based on user score. PMCC has a value between -1 and 1 that measures how related a couple of quantitative variables are.
Let’s factor this process into a couple of functions to recommend movies to a certain user by the correlation matrix of all movies.
To check how the developed functions work, we’re going to recommend movies to user 21 for example, who has seen the following movies with their corresponding rating.
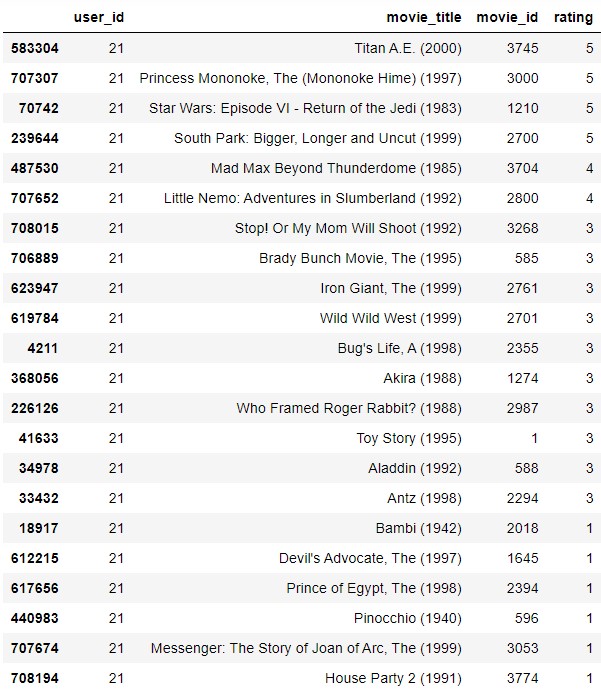
We send to the function get_movie_recomendations the list of movies that the 21 user has seen to give us the list of recommended movies (user_film_21_list).
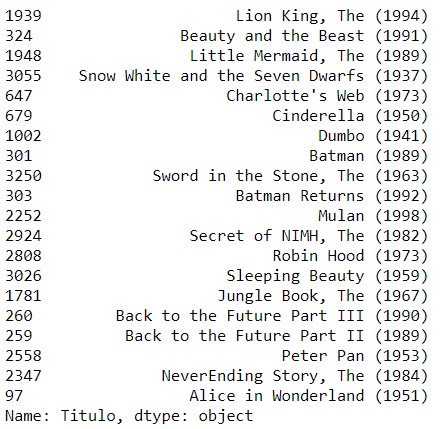
We get the top 20 movies that will be the movies with the highest correlation to the movies that user 21 has already seen.
Web project in Github