
Financial market data is one of the valuable data to analyze the potential to detect an organization’s financial problems. Among some of them, Yahoo Finance is one of those websites that provide free access to these valuable stocks data, commodity prices and cryptocurrencies among others. In this post, we will try to implement a simple web scraping in Python that will help us extract the data provided by the Yahoo finance website. Subsequently with this data once collected from Yahoo can be used to generate a model to forecast stock prices, predict market sentiment towards a stock, gain an investment advantage and trade cryptocurrencies, etc. In addition, the process of generating investment plans can make good use of this data.
Approach for scraping Yahoo finance data
Yahoo finance provides a wealth of information about the stock and investment market. Our main goal is to obtain the data by scraping Yahoo’s finances and store it in our own data frames for further analysis in other articles that we will be developing.
The easiest thing would be to work with Python libraries called Scrapy or Beautifulsoup. However, this time we preferred to write the code that would «peel the onion» of the Yahoo Finance Key Statistics HTML from scratch because Yahoo’s HTML had small variations in the tags that could make our life hell if she used scrape libraries.
That’s why we’re going to scrape the data from Yahoo’s fiances and extract the market stock data using the simply Python libraries urlib, numpy and Pandas.
We started looking for the values that she saw on the original page in the source code, with the intention of understanding how Yahoo’s HTML was built, it did not take long to identify that she simply had to look for the concept she wants with a «>» at the beginning and then the tags </ td></ tr> at the end. For example: «> Market Cap» and «</ td></ tr>». For example, we review a specific case such as Google (GOOG) (https://finance.yahoo.com/quote/GOOG/key-statistics?p=GOOG) or any other company by changing the acronym.
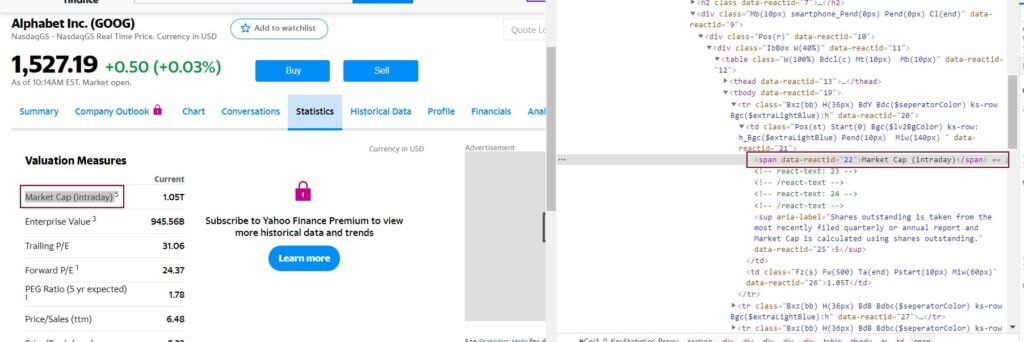
Once we have detected the fields that we want to extract, we list the name of the fields to get the data of each of the companies.

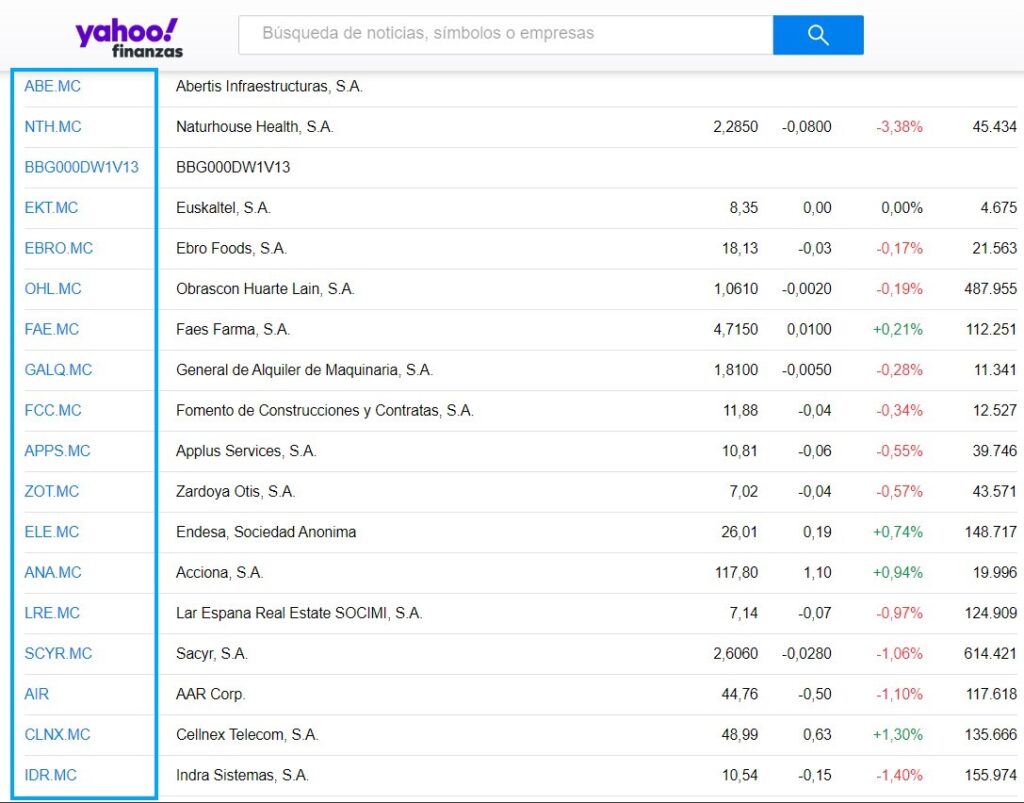
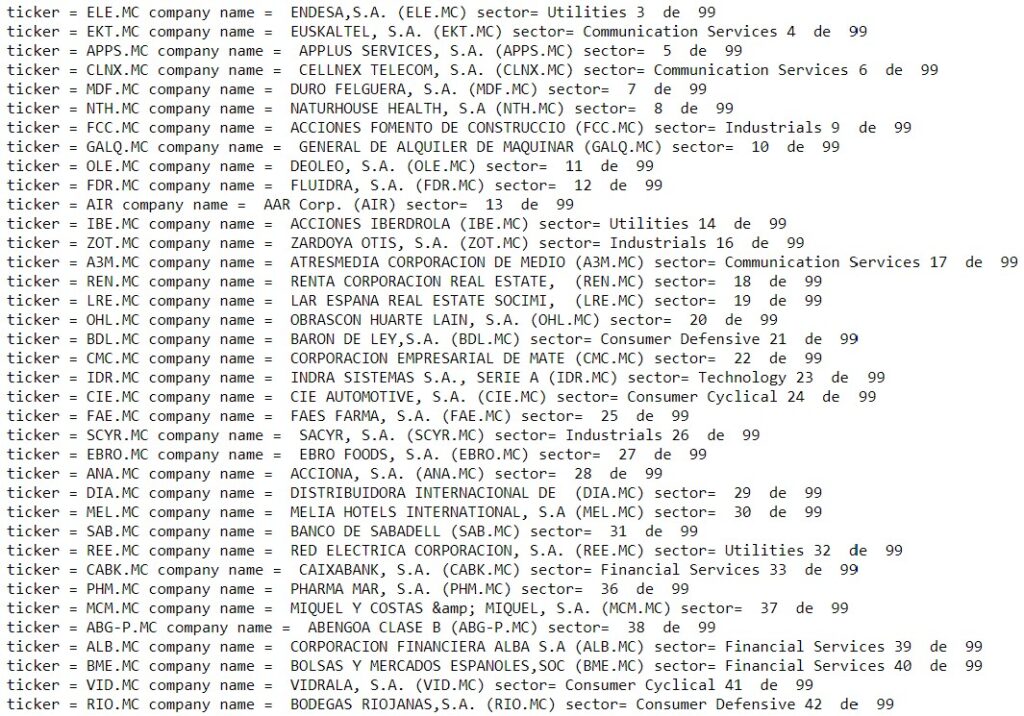
Then we’ll have to get the acronyms (tickers) with which yahoo finances tag companies to locate the data that operate on the Madrid stock exchange, from the corresponding section in the Spanish version of Yahoo finances.
We extract all HTML content from the web.
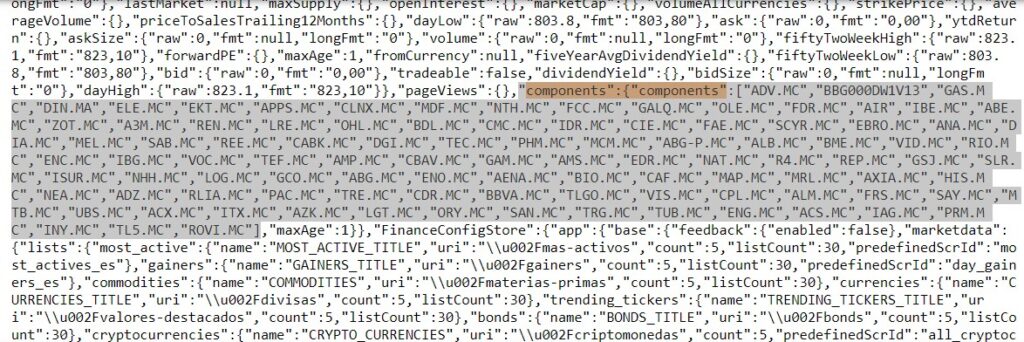
And we extract the available list of all existing tickers in downloaded HTML tags.

Before generating a data frame, we verify that tickers are extracted correctly and what their data types are.
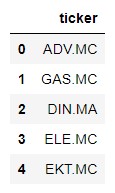
We generate a new data frame to enter the extracted tickers and remove some ticker whose format does not match the acronyms used by Yahoo
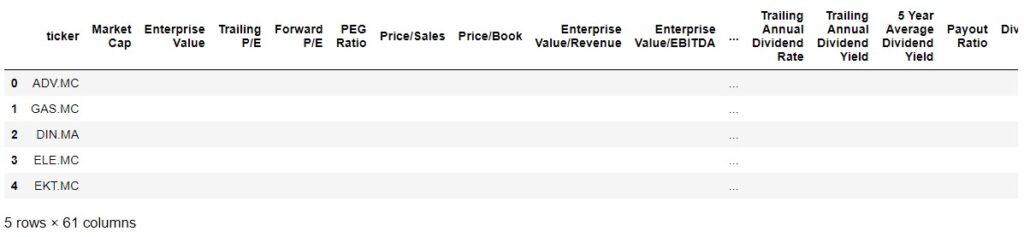
We add to the data frame the fields selected anteriorly in list_of_fields that we are going to extract from each company.
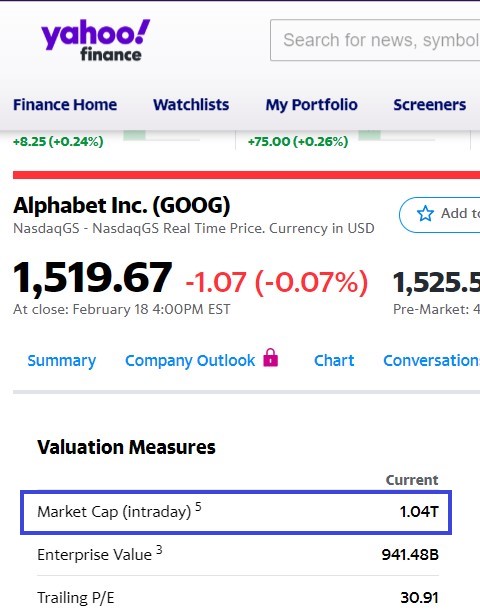
For the development of the complete data extraction function, let’s test the simplified extraction for each of the tickers (company). For example, we’ll use Google’s ticker (GOOG). On the Yahoo Finance website, we go to the company’s statistics section and download all the HTML tag content from the page. Once with the full content, we look for the corresponding fields and extract the data to the data frame.
Now we test a complete extraction of the data from all selected fields within the page of the same company.
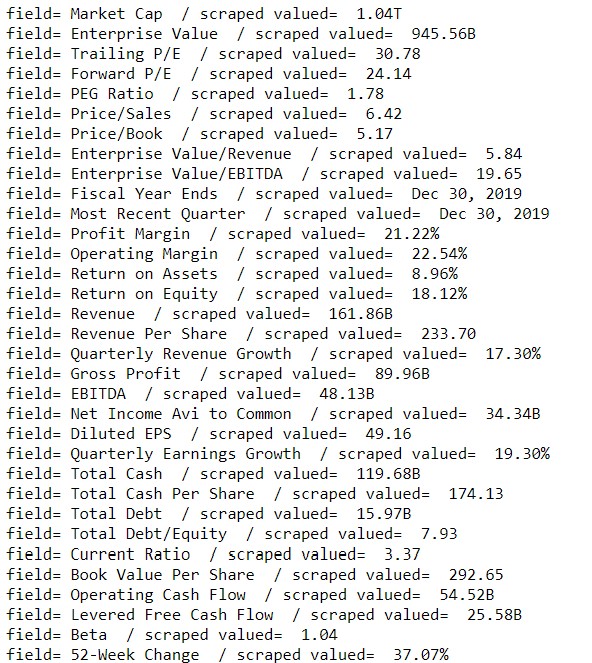
Now we combine the different tests carried out to define a function that travels each tikers, extract the name and statistical data of the company and the sector and industry from the profile web. Keep in mind that we must handle potential connection errors and possible null values for the function to continue when it encounters any of these assumptions.
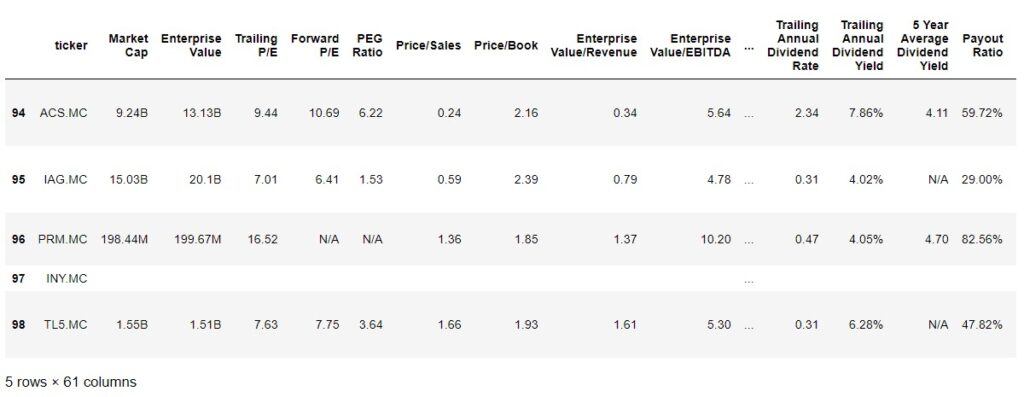
Finally, we see how the values have been inserted into the created data frame.
In a later post, we will try to show other options of scrapping data from Yahoo finances to evaluate the different methods.



Un pensamiento en “Madrid Stock Exchange Scrape Yahoo Finance Data with Python”
Comentarios cerrados.